ISO 20022 — Navigating rich semantics
ISO 20022 — Navigating rich semantics
ISO 20022 — Navigating rich semantics
December 13, 2023
Rich means complex
Our recent article ISO 20022 — An enabler for AI (and BI) discussed the potential of ISO 20022 as a strategic data asset. We acknowledged the challenges posed by its complex structure and granular content, and we explored the essential components of a data pipeline designed to take advantage of it.
Now, in this article, our focus shifts to the crucial aspect of data access and information retrieval from ISO 20022. Our goal is to simplify ISO 20022 data for those responsible for managing it: business analysts, data analysts, data scientists, data engineers, data architects, and data strategists.
We’ll provide practical insights, ensuring that armed with this knowledge and the right tools, everyone can play a pivotal role in connecting the business, data, and technology for the new lingua franca of payments.
A tree-like backbone
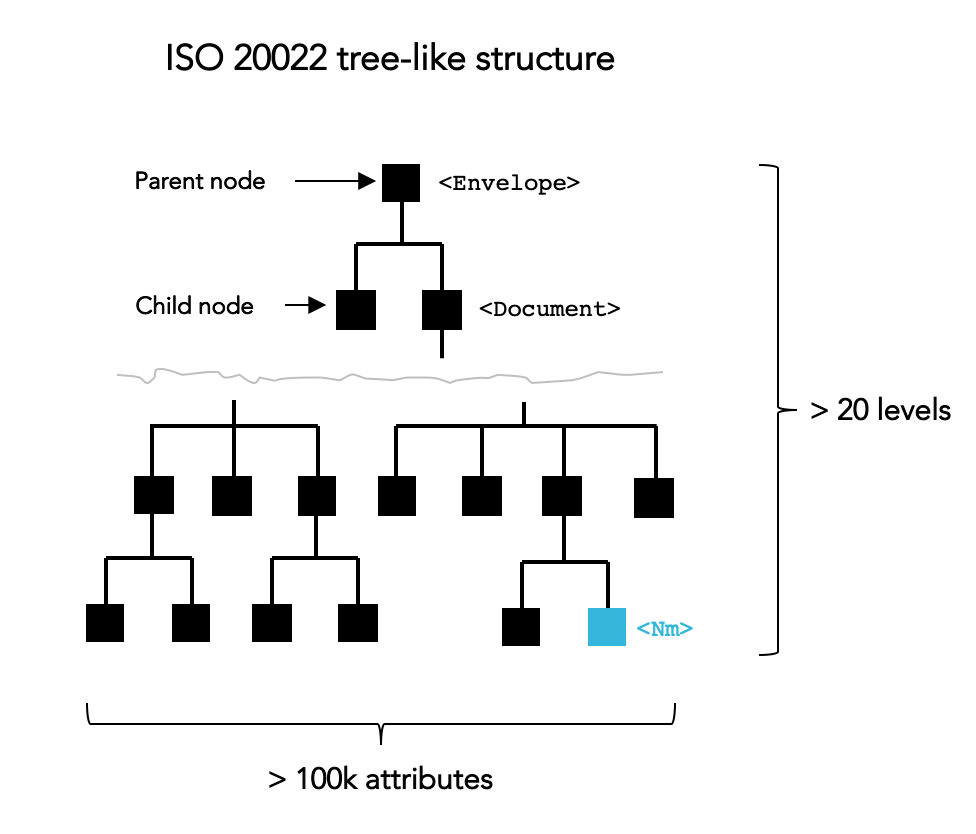
ISO 20022’s native data model resembles a tree [1], a hierarchical arrangement of parent and children nodes (Figure 1). This structure, akin to ISO 150022 and its divisions into sections and subsections, organizes content into interconnected business components (e.g. Credit Transfer containing Creditor containing Party containing Name). This natural hierarchy finds expression for example through JSON or XML syntax. In the latter scenario, each node is assigned a tag that signifies its corresponding data item, such as <Nm> representing a name in the example below. ISO 20022 presents a vast and detailed tree structure, with numerous levels of depth and hundreds of thousands of contextualized attributes (i.e. path combinations) across the more than 700 message types defined to date [1].
Approaches to Information Extraction
When it comes to extracting information from ISO 20022, there are essentially two methods to consider. Let’s name them transactional-oriented and analytics-oriented extractions.
Transactional-Oriented Extraction
This is the traditional, scoped, and deterministic approach, commonly favored. It involves segregating various message types, possibly breaking them into fragments, and mapping these components to canonical data models tailored to specific business areas and use cases. Essentially, you narrow down the extraction to specific message types and necessary attributes, build a rigid schema model with more or less lengthy queries, and deploy a rule-based engine on this data. The approach relies on minimal changes to both the data and the rules moving forward. It is apt for stable, transactional scenarios such as routing and rule-based processing applications. However, it inherently leads to the creation of data silos, something many companies aim to sidestep, particularly when venturing into analytics.
Analytics-Oriented Extraction
Alternatively, we propose leveraging ISO 20022 in its raw form, preserving the rich context it offers that spans across business transactions, use cases, business divisions, financial institutions, and market infrastructures. This requires a schema-flexible holistic data model that captures all data, navigating the entire data workflow from ingestion to processing, storage, extraction, and decision-making by downstream analytics — both by humans (business intelligence) and machines (artificial intelligence) — working hand-in-hand.
Tree-like structures, common in computer science and business applications, naturally align with financial transactions. They contextualize data items of the same nature: party details, transaction details, financial instrument details, etc. While concise forms are easily scanned by humans or machines, in a comprehensive form like ISO 20022 and with the holistic view in mind, different extraction strategies are required.
The figure below (Figure 2) illustrates three ways to access a data item tagged with <Nm> with varying degrees of reliance on its data coordinates or paths.
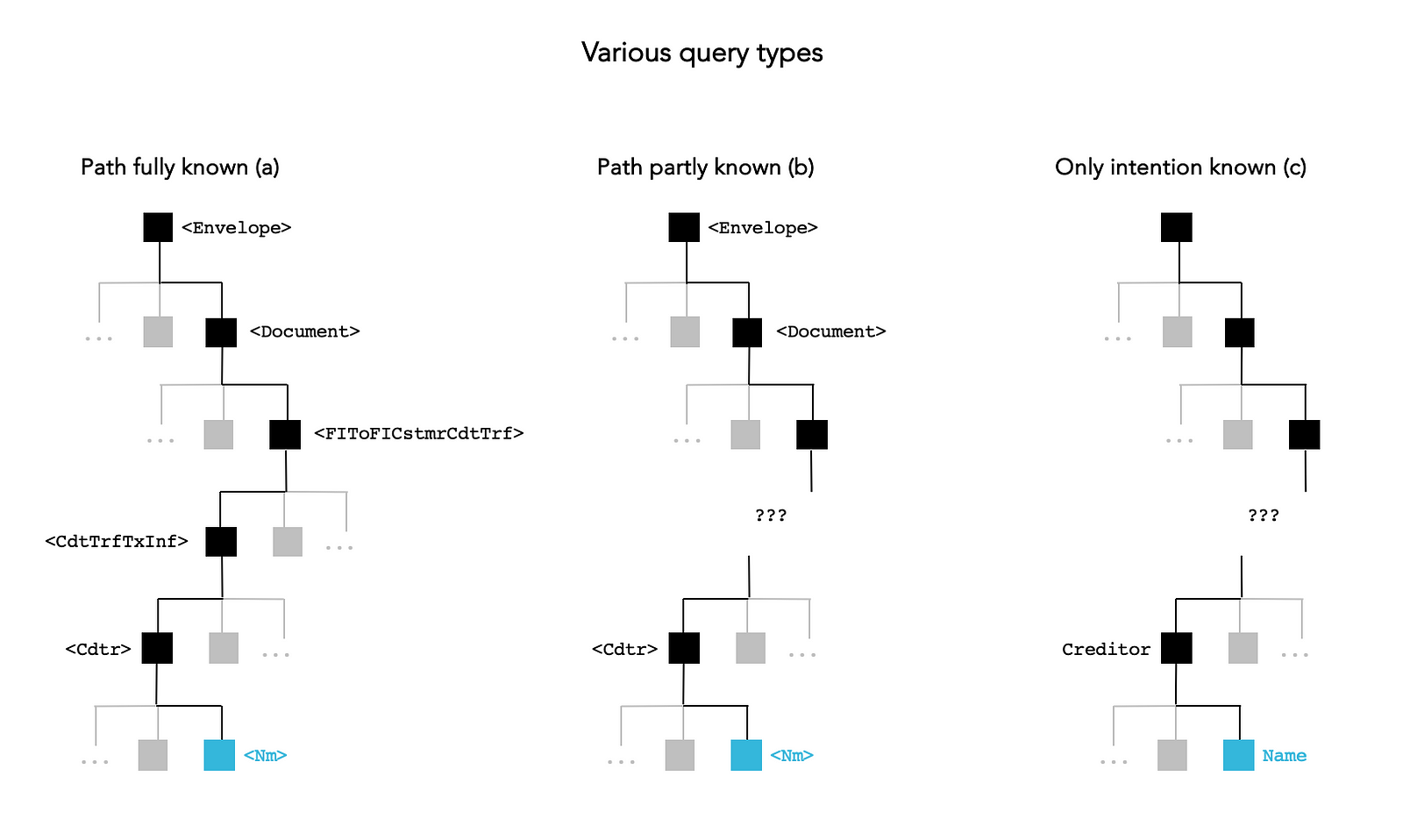
Case (a) — If the complete paths of the required data items (e.g. for accessing the creditor’s name <Nm>) are known, you can construct queries to extract them using your preferred language (e.g. JSONPath, XPath). This method is acceptable when dealing with a small number of queries. However, if aiming to extract 1000 attributes this way, it would require 1000 queries.
Case (b) — When only a portion of the path is known (e.g. tags between <Document>and<Cdtr>are uncertain or the knowledge is limited), you might try to apply recursive search, but this could result in compute-intensive searches within the database and lengthy, complex queries. A more effective approach is to use a helper to navigate the metadata store.
Case (c) — When only the intention of the query is known (e.g. needing the creditor’s name), and there’s no upfront knowledge of the exact relevant attributes required for the use case, a semantic search helper becomes essential to identify potential matches.
While case (a) is more aligned with transactional-oriented extraction or very scoped analytics, cases (b) and (c) emerge as preferred extraction methods for investigative, “data-hungry” scenarios. These cases typically involve delegating the selection of the best attributes to machine learning, incorporating feature engineering and selection.
Let’s take a concrete and simple example.
The Investigation Use Case
Picture yourself as a data analyst immersed in a challenging anti-money laundering case, armed only with the knowledge that the necessary information lies within the ISO 20022 dataset, possibly in specific message types. While there are a few known attributes, the exact paths in the data model are uncertain.
For example, imagine you receive a request like from the compliance expert:
Please find all possible information related to a creditor named Jack London with an address in New York. You should find all the data you need in our ISO 20022 payment database, in the messages pacs.008 or 009, maybe also in pain.001.
While you are certain you’re interested in data items located under <Cdtr>(creditor) you lack clarity on the exact paths, both for up-level and down-level paths. This places you in the cases (b) or (c) discussed earlier.
In response, you decide to consult the metadata catalog containing the ISO 20022 specifications [2] for the 3 message types in scope. Below are the summary tables of your findings (Table 1–3).



As you embark on the quest to extract information related to <Cdtr>, your initial exploration in the ISO 20022 specifications [2] reveals 3 potential up-level paths for <Cdtr>, and using a comprehensive structured address you get 15 possible tags under <PstlAdr> [3], so 16 down-level paths counting <Nm>, that is a total of 48 paths. You receive at this point another ask:
Please also check if Jack London appears as a debtor.
Considering the inclusion of <Dbtr>, you assume you can multiply this number by 2, arriving at 96 potential paths. Just as you diligently craft queries based on these assumptions, the compliance expert introduces an additional request:
Please also check if Jack London appears as an ultimate creditor orultimate debtor.
You know this relates to the tags <UltmtCdtr> and <UltmtDbtr>, so that the path count multiplies. You find yourself drowning in a sea of possibilities. Your time is consumed by requesting and collecting new attributes, leaving little room for the core investigation.
Feeling overwhelmed, you decide to pivot and try a different approach: text search. You design your query to capture all message payloads containing London and New York, ensuring nothing is overlooked. After running the query for long minutes on millions of entries, you realize the results are flooded with all payment messages sent and received in London and New York, plus unexpected messages like bills addressed to New York Café in Budapest or Paris. The manual querying process becomes a formidable challenge, emphasizing the need for a more efficient and refined approach to handle complex investigations.
Harnessing Semantics: A Crucial Asset
Within ISO 20022, each data item in a message is distinguished by a unique feature — an associated metadata item, or put differently, a path. This path acts as a key, granting access to the data item and unlocking the wealth of content it contains. While this feature introduces the complex structure discussed, it also signifies a substantial capability inherent in ISO 20022. Let’s revisit our example to illustrate.

One can say that the data item New York within the message is deeply contextualized within the business transaction. In fact in a typical message, the space occupied by metadata surpasses that used by the data itself.
Another striking feature of ISO 20022 is that these metadata elements inherently convey semantics. In other words, they directly encapsulate meaning and information about the data they accompany. Furthermore, the content can be directly translated into plain English, albeit with a touch of banking jargon.

Therefore, the data item New York comes accompanied by an extensive context, elucidating its significance in the specific transaction. This approach eliminates the need for obscure encoded data coordinates (e.g., tag 59in MT 103 or tag58in MT 202) to discern the content’s meaning, enabling the use of human language to query the data.
To sum up, one can say that the data catalog is seamlessly integrated into the message, employing English jargon to articulate and describe its content. This characteristic stands as a fundamental aspect of ISO 20022.
Proposed Solution: Guided Queries Using Metadata
We present a solution to assist users in formulating queries through a structured process:
1) Plain English Query: The user formulates a query in plain English or includes ISO 20022 tags in it.
2) Metadata Contextualizer: Our system identifies the most relevant attributes to be extracted based on the user’s query, providing graphical and statistical indicators to assist in user validation.
3) Query Builder: A valid query (e.g. SQL) is automatically generated using the identified attributes, which can be potentially validated by the user.
4) Query Execution: The system executes the query across various databases, providing the user with the results for downstream analytics.
The user benefits by being able to issue open requests, either using precise attributes or natural language, and gain holistic access to the entire content related to the investigation scope. This approach reduces the time needed to construct queries, minimizes noise, and delivers a structured data asset ready for use in business intelligence (BI) tools (e.g. Excel, SQL, Tableau, PowerBI), traditional artificial intelligence (AI) applications or generative artificial intelligence (GenAI).
Summary
ISO 20022 introduces a rich and well-structured object, necessitating tailored approaches for efficient navigation and information retrieval to fully exploit its potential. A noteworthy feature of ISO 20022 is its incorporation of a metadata description rich in semantics within the message, with paths formulated in English using banking jargon. This characteristic can be utilized to help users construct queries, ensuring access to relevant and precise data tailored to their specific use case.
Next step
All the solutions mentioned in this article are embedded in our products Swiftflow and Swiftagent. Reach out directly to info@alpina-analytics.com to discuss your use case or visit Alpina Analytics for more information.
About Us
Pierre Oberholzer is the founder of Alpina Analytics, a Switzerland-based data team dedicated to building the tools necessary to make inter-banking data, including Swift MT and ISO 20022, ready for advanced analytics.
George Serbanut is a Senior Technical Consultant at Alpina Analytics supporting Swiftagent — a conversational interface to navigate and query Swift MT and ISO 20022 data.
We’ve confronted these challenges for years in real-life, high-risk application contexts, and we understand that banks need long-lasting proven expertise to mitigate risks, rather than quick wins that never make it to production.
References
[1] https://en.wikipedia.org/wiki/Tree_(data_structure)
[2] https://www2.swift.com/mystandards/#/c/cbpr/samples
[3] https://medium.com/@domdigby/iso-20022-enhanced-data-structured-addresses-c64c645cc161