ISO 20022 — Address structuration
ISO 20022 — Address structuration
ISO 20022 — Address structuration
January 02, 2024
A solved issue ?
We observe that both state-of-the-art large language models (LLMs) such as GPT-4 and specialized packages combining machine learning (ML) and natural language processing (NLP) like Libpostal deliver quality results.
Nevertheless, expanding the present evaluation to include additional real-life test data from financial institutions, validated with geocoding, is highly recommended to draw reliable conclusions.
Find the detailed results here.
Context
The ISO 20022 standard is gradually replacing various legacy data standards for payments across the world, offering a significant advantage by providing more structured and richer data. While our previous articles [1,2] have explored the processing and information retrieval of this enhanced data post-migration, it is essential, during the migration phase, to acknowledge that “a message is essentially a container, but if you don’t know the structure of what you put in that container, you have a problem” [3].
This challenge is particularly evident in the context of party data, namely the information related to the entities involved in financial transactions, in particular for postal addresses. Although the structured framework already exists in ISO 20022, populating structured addresses with detailed data elements proves to be demanding.
This article undertakes an examination of several solutions capable of structuring addresses, or say differently to translate addresses from unstructured data into a structured format. It explores the potential integration of cutting-edge large language models (LLMs) alongside other existing machine learning natural language processing (ML/NLP) approaches to determine the most effective means of addressing this issue.
Challenge
While the structured representation of party data promises to enhance the efficiency of anti-financial crime (AFC) and operational processes [4], the current reality is that party data is still commonly exchanged in an unstructured or loosely structured format, especially in the early versions of ISO 20022 inherited from MT, still widely used by the way. The transition from unstructured to structured party data represents a big challenge (see Figure 1).

In essence, there are two distinct “locations” in the workflow where data structuration can take place:
1) At the boundaries — This involves capturing granular data elements across all user and application interfaces.
2) In the flow — This entails translating unstructured data into a structured format and facilitating exchange between applications.
One one hand, the option 1) necessitates a comprehensive refactoring of existing processes and systems, but will be ultimately the most reliable and strategic option in the long run to be natively structured. Meanwhile, the phased transition to structured party data capture implies that the realization of its benefits will occur gradually, marked by the pace dictated by the system within the payment chain dealing with the most substantial data limitations [4]. This limitation is even currently raising questions about the feasibility of attaining a fully standardized data structure by 2025 [5].
On the other hand, the option 2) presents a tactical solution that allows for the realization of benefits through conversion while concurrently working on option 1). This may not necessarily involve a full-scale implementation across entire markets or end-to-end transaction chains, but can be applied already within the confined scope of a specific financial institution (FI). Also, it’s crucial to note that option 2) can be internally implemented within a financial institution’s master data or just-created messages, for instance, through batch-type processing. Even less intrusively, the structuration can be performed as a parallel job (e.g. for sanction screening) leaving the messages sent to the market untouched.
But this alternative is not without its challenges, extensively elucidated in the literature [6,7]. Transforming postal addresses poses significant challenges, particularly in terms of generalizability across the globe. A few examples include:
- Variability in address formats: addresses can be written in various formats, and there is no strict standardization. Different countries, regions, and even individuals may use different conventions for expressing the same information. For example, the placement of elements like street names, house numbers, and postal codes can vary widely.
- Multiple languages: parsing systems need to be capable of handling multilingual input and recognizing address components regardless of the language used. This adds complexity to the parsing process.
- Abbreviations and synonyms: people often use abbreviations, synonyms, or alternate names for streets, cities, and other address components. Parsing systems need to account for these variations to accurately extract and interpret the information. For instance, “St.” and “Street” might be used interchangeably, or “NYC” and “New York City” could refer to the same location.
Experiment
We opted to utilize a set of only 9 addresses for our test (see Table 1 and 2).
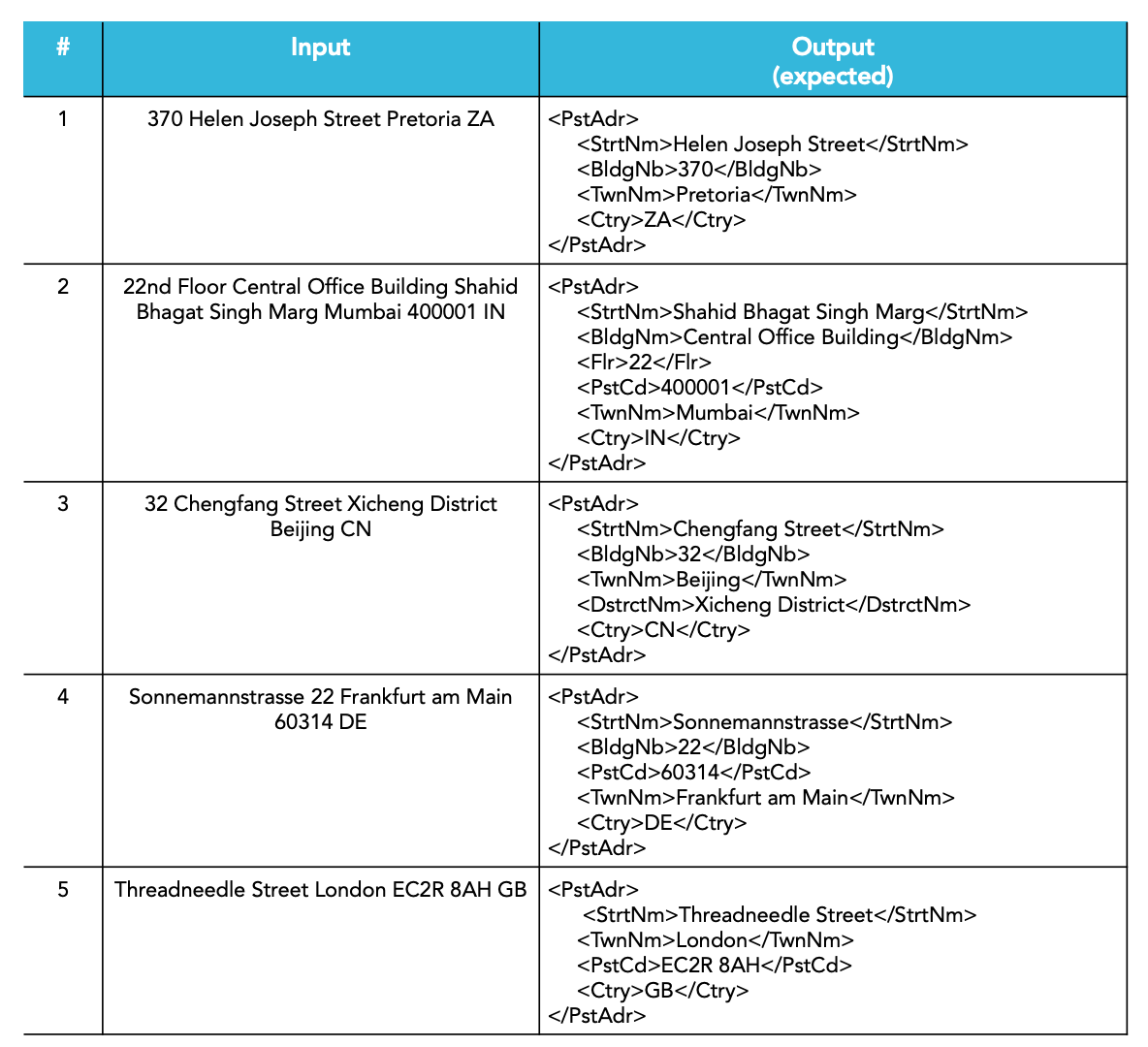
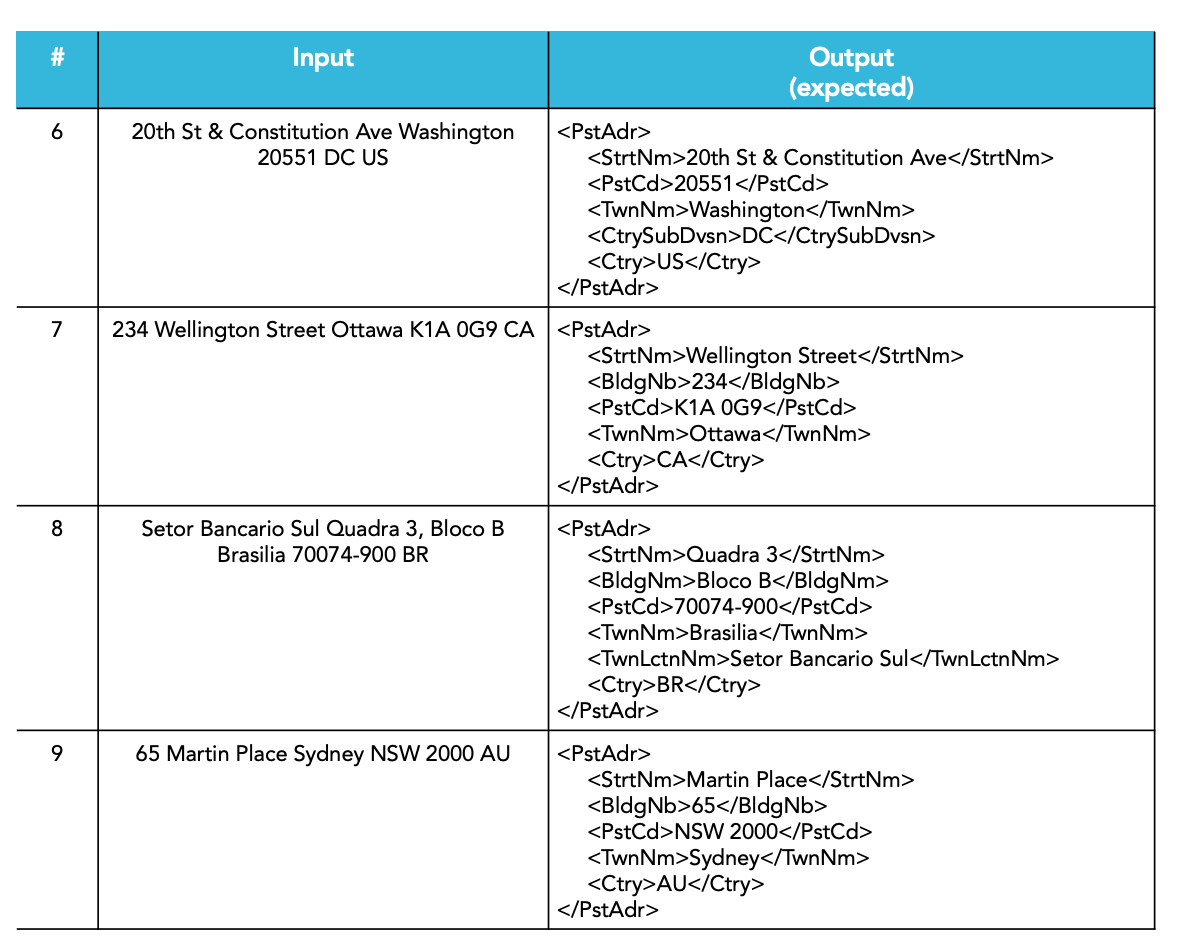
This selection satisifies the following criteria:
– Set proposed, reviewed, and also tested by an ISO 20022 expert [8].
– Covers different regions of the world with existing entities.
– Allows for manual interpretation of the results.
While this may be deemed a modest dataset, we encourage all readers of this article to actively engage with us to conduct validations on real-life data. Indeed, testing solely on dumped production data can conclusively determine whether the chosen method can achieve the desired trade-off between performance and risk-appetite.
Solutions
All the outlined solutions below were tested programmatically, and the results were automatically measured. The models/packages were used out-of-the-box, and no fine-tuning was performed. The written code serves as wrapping code and can be shared upon request.
The following protocol was systematically applied:
1) Pass the input text as per the above table. It’s important to note that we chose a conservative approach, consolidating the entire input text into a single inline input, conscious that the division of content across multiple <AdrLine> lines might yield slightly different results.
2) Perform the parsing using the model/package of choice, passing a prompt if required (see below).
3) Convert the output into an unordered JSON-type object, if not already given as an output.
4) Post-process the obtained JSON, such as removing empty elements.
5) Convert the cleaned JSON into an ordered XML ISO 20022 compliant output.
LLM-based solutions
Large Language Models (LLMs), leveraging their contextual understanding of language, emerge as excellent candidates for address parsing. Their capacity to grasp context enables them to decipher intricate address variations, language-specific structures, and nuanced expressions, making them highly proficient in navigating the inherent complexity of diverse address formats worldwide. Moreover, their effectiveness is complemented by user-friendly interfaces, particularly through well-crafted human readable prompts (see below) that facilitate their application with ease.
For our experiment, we selected four LLM models that reflect the current state-of-the-art developments as of the beginning of 2024:
– GPT-4: Widely acknowledged as the most generalist model to date, developed by OpenAI.
– GPT-3.5 Turbo: Selected for comparison owing to its free access, reduced complexity, and quicker execution time, also from OpenAI.
– Palm 2 Text Unicorn: Introduced by Google as a challenger to GPT models (Gemini not available in Europe to date)
– Llama 2 70 b: Open-source challenger model developed by Meta.
Although other open-source models were considered for the exercise, they were not retained due to their subpar performance. We use out-of-the-box models without any fine tuning.
We primarily utilize the following prompt to instruct these LLMs. Also this is subject to improvement and we are curious to hear of prompts leading to better results.I will give you a postal address string as input.
I would like you to categorize each subsequence within the string into the categories given by the below specification, and return a valid JSON.
This is the specification:
('Dept', 'Department'),
('SubDept', 'Sub Department'),
('StrtNm', 'Street Name'),
('BldgNb', 'Building Number'),
('BldgNm', 'Building Name'),
('Flr', 'Floor'),
('PstBx', 'Post Box'),
('Room', 'Room'),
('PstCd', 'Postal Code'),
('TwnNm', 'Town Name'),
('TwnLctnNm', 'Town Location Name'),
('DstrctNm', 'District Name'),
('CtrySubDvsn', 'Country Sub Division'),
('Ctry', 'Country Code (2 letters acc. to ISO 3166 Alpha-2)')
Requirement 1: You must return a valid JSON string without any line splitter or whitespace betweemn the fields.
This is the postal address input: <input>
ML/NLP-based solutions
Non-LLM solutions, including traditional machine learning natural language processing based parsers (ML/NLP), stand out as strong candidates for address parsing assignments. These models, when fine-tuned and specialized, exhibit robustness in addressing specific nuances. While their adaptability and effectiveness depend on meticulous pre-processing crafting, they present viable alternatives to LLMs. They not only provide complete transparency in their mechanics when open-sourced but are also purposefully designed for the task, incorporating principled design. Additionally, they can be run on-premises, ensuring no exchange of sensitive data with a third party, while delivering exceptionally fast execution times.
Our chosen challenger in this category is:
– Libpostal: Acknowledged as the de facto most generalizable library to date, trained with over 1 billion records from open data (OpenStreetMap, OpenAddresses, etc.) [6,7].
Although other open-source packages were initially considered for the exercise, they were not retained due to their subpar performance.
Disclaimer
We chose solutions based on prevalent packages and models in online communities that are readily deployable without fine-tuning. While we acknowledge that our coverage may not be exhaustive, we eagerly welcome recommendations from our readers for any other relevant options. Your insights and suggestions hold great value for us.
Out-of-scope : geocoding !
While parsing addresses is a vital initial step in content structuration for the ISO 20022 community, the current discussion deliberately omits geocoding. However, it’s imperative to note that geocoding, the process of converting addresses into geographic coordinates, is regarded as a critical, if not mandatory, subsequent step. This step is integral for enabling machine readability and facilitating location-based decision-making processes.
Results
The below table (Table 3) shows the results overview obtained for the solutions selected.
For a comprehensive view of the detailed results, please refer to the detailed results here.
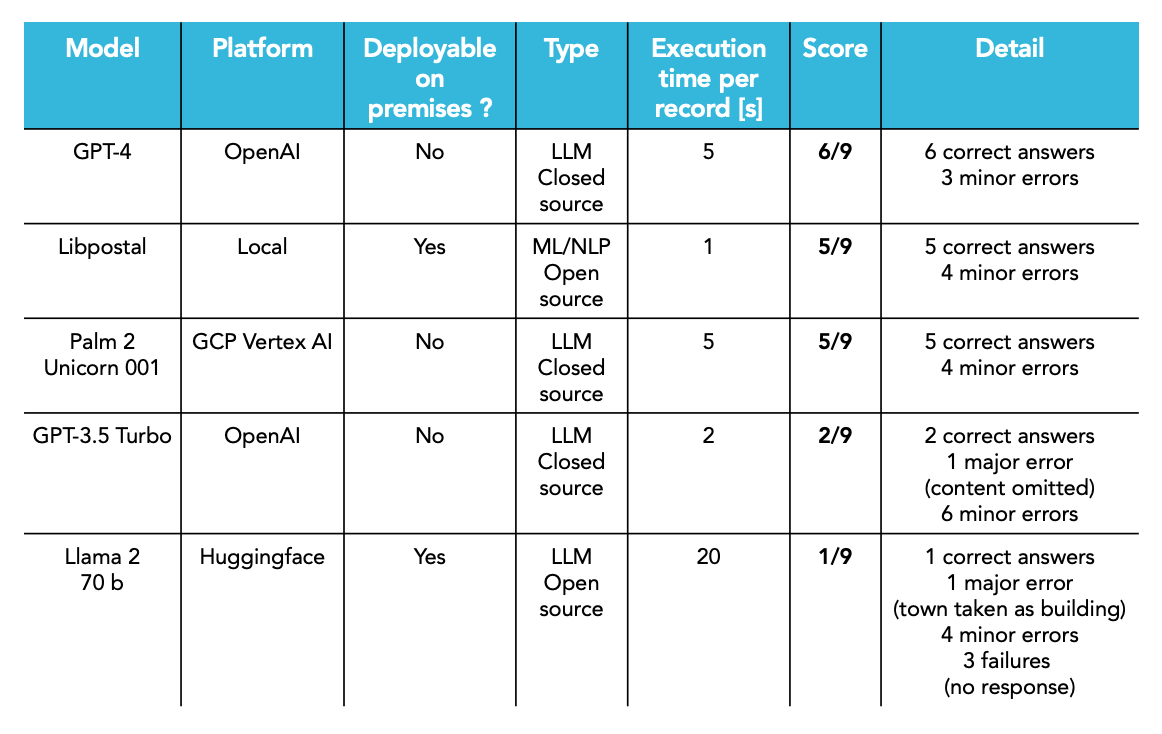
The main column of interest is the Score column. It indicates how many answers out of the 9 samples were correct, while the Details column specifies whether major or minor errors were obtained, or even failures in some cases.
- Correct answer: the reported score in the table corresponds to the JSON comparison made in the
check_jsoncolumn of the detailed report. The XML comparisoncheck_xmlis given here for completion purpose but can be left to fine-tuning in respect of the exact expected ordering. - Major error: some content was omitted (e.g.
<BldgNb>or portions of<StrtNm>) that wouldn’t allow the party to be found unambiguously - Minor error: some content was attributed to a slightly different tag than expected (e.g.
<CtrySubDvsn>instead of<PstCd>) - Failures: no answer or no usable answer was provided
Additionally, for indicative purposes, the Execution time per record column provides a rough estimate of the execution time taken by the model/package for each record. Though not conducted under production conditions, it provides a preliminary sense of the relative performance of the solutions compared to each other.
Discussion
Only three solutions — GPT-4, Libpostal and Palm2 — yet tested here on a tiny dataset, demonstrate a results set devoid of major errors. Other solutions mentioned in the study appear to exhibit clear shortcomings. Again, a wider dataset, more complex prompts, and model fine-tuning might lead to different rankings
As we release this article in early 2024, notable concerns are arising regarding the use of centralized closed source LLMs managed by third parties. These concerns encompass issues related to copyrighting, transparency, stability, and data protection, not to mention pricing, licensing and infrastructure requirements. Those can be mitigated by using smaller size open source LLMs fine tuned on specific task and data.
As an alternative to LLMs, the Libpostal package offers the advantage of being deployable entirely on-premises, boasting fast execution times and providing full transparency on internal mechanics, while using only open data for its training.
Therefore, we recommend a careful consideration of project requirements to select the optimal solution for the use case. Furthermore, as discussed briefly below (see Next Step), geolocation is suggested as the ultimate validation method to consider subsequently of address structuration.
Next step
Our product Swiftflow embeds the Libpostal package as a parser, but can also connect to third-party LLMs like GPT-4 or Palm 2. Furthermore, Swiftflow goes beyond mere address parsing by incorporating geolocation functionalities. This enables the validation and precise location of given addresses on the Earth’s map, representing the ultimate validation needed for your existing data. Without this geolocation validation, your verification process may be susceptible to human judgment, interpretation, and errors, ultimately resulting in translations that are not optimized for the specific use case.
Therefore, we strongly recommend complementing any type of translation with a dedicated validation using a substantial amount of real-life data from your institution. Ideally, this validation should be augmented with geolocation validation, a capability offered by our tool Swiftflow. Importantly, this process can potentially be entirely realized on-premises.
We are eager to engage with you to expand the current study and validation to incorporate your own messages. Your input and collaboration will contribute to a more comprehensive and tailored understanding of the solutions in your specific context.
About Us
Pierre Oberholzer is the founder of Alpina Analytics, a Switzerland-based data team dedicated to building the tools necessary to make inter-banking data, including Swift MT and ISO 20022, ready for advanced analytics.
George Serbanut is a Senior Technical Consultant at Alpina Analytics supporting Swiftagent — a conversational interface to navigate and query Swift MT and ISO 20022 data.
We’ve confronted these challenges for years in real-life, high-risk application contexts, and we understand that banks need long-lasting proven expertise to mitigate risks, rather than quick wins that never make it to production.
References
[1] https://medium.com/@pierre.oberholzer/iso-20022-an-enabler-for-ai-and-bi-0c2a54042c6c
[2] https://medium.com/@pierre.oberholzer/iso-20022-navigating-rich-semantics-7571ea76f8a2
[3] https://www.bnymellon.com/us/en/insights/aerial-view-magazine/smart-messaging-and-the-payments-revolution.html
[4] https://medium.com/@domdigby/iso-20022-enhanced-data-structured-addresses-c64c645cc161
[5] https://www.linkedin.com/pulse/iso-20022-structured-addresses-ordering-beneficiary-data-haribabu/
[6] https://medium.com/@albarrentine/statistical-nlp-on-openstreetmap-b9d573e6cc86
[7] https://medium.com/@albarrentine/statistical-nlp-on-openstreetmap-part-2-80405b988718
[8] https://lnkd.in/dayYTem7