TxAgent: An ISO 20022 AI Agent Industrialized with Massive Parallel Testing
TxAgent: An ISO 20022 AI Agent Industrialized with Massive Parallel Testing
January 27, 2026
Abstract
Banks and large enterprises are under pressure to accelerate payments investigations with AI across Compliance, Treasury, and Operations. Not just faster findings. AI also needs to produce results that are reproducible, evidence-backed, and audit-ready, otherwise most initiatives never move beyond a pilot [3].
TxAgent is the answer of Alpina Analytics to that challenge.
TxAgent is an AI investigation assistant grounded in ISO 20022 payment transaction data designed to produce evidence-backed answers that can be used by humans or embedded into downstream systems.
This article covers a less visible but critical part of TxAgent: how we industrialize it with evaluation-driven development and massively parallel regression testing on Step, Exense’s platform used for over a decade to validate business-critical systems in large banks and insurers.
For a more technical view of the same joint demonstrator, Exense also published a deep-dive on the Step testing setup and protocol: “Testing of AI Agents with Step” [8].
ISO 20022 was not just a migration. It was a complexity upgrade.
The ISO 20022 standard is now the main standard for payments messaging worldwide. Most banks have focused on the migration itself: keeping payments running, updating systems, and managing operational risk. That phase is now largely behind us.
In the business lines, banks now face a new level of complexity in day-to-day investigations:
- Richer and more structured payment data [1]
- Many new fields and nested structures [2]
- More flows across payment types and clearing systems
- Uneven adoption across counterparties
- More optional fields, more variants, more edge cases
- An evolving language
The ISO 20022 standard was designed to improve clarity. In practice, it also increases the amount of context teams need to review, so processes and tooling must evolve with it [4].
Compliance investigators now work with richer context, creating both opportunity [6] and additional complexity. Treasury teams have access to more detail, but turning it into timely, actionable cash signals still requires better integration and tooling [5]. Operations teams face more repair cases and exceptions. Many investigation workflows and tools were designed around simpler message formats and single-case reviews. With ISO 20022, investigations more often require navigating richer structures and linking context across message chains and systems.
The format changed, but more importantly, the investigation workload changed.
TxAgent: Evidence-Backed Investigations in Minutes, Not Hours
TxAgent is designed for one job: helping bank teams investigate transactions quickly and safely. Think of it as an investigation assistant that can read ISO 20022 payments like a specialist and answer questions in plain language. It can be used directly by investigators, or embedded into upstream and downstream systems through APIs (including agent-to-tool and agent-to-agent patterns), always grounded in the underlying transaction data.
Typical investigations include:
Compliance (AML and screening investigations)
- Who are all the parties involved in this payment chain, and what roles do they play ?
- What addresses and identifiers are associated with this counterparty across related messages ?
- Which other transactions share the same ultimate beneficiary ?
Treasury (liquidity insight from real flows)
- Where are settlement delays building up in the selected period ?
- Which corridors or counterparties drove the most volume this week ?
- What is the average lag between key message events, by currency or counterparty (where timestamps are available) ?
Operations (exceptions and repair patterns)
- Which fields are missing or malformed in this rejected payment, and what is needed to release it ?
- What do successful payments to this corridor typically look like ?
- Which counterparties generate the most exceptions in the selected period ?
The key point is not that TxAgent “talks”. It is that it can investigate. And in a bank, an investigation assistant only matters if its output is:
- Correct enough to be useful
- Explainable enough to be trusted
- Reproducible enough to be defensible
That is why TxAgent is built around evidence trails.
Instead of producing a confident-sounding paragraph, TxAgent shows its work. It lays out the investigation steps it followed, points to the exact fields and facts it relied on, and highlights the messages and the cross-message links that shaped the conclusion. When data is incomplete, it makes the boundaries clear and flags uncertainty rather than guessing.
In Compliance and Treasury, speed matters, but defensibility is what makes a result usable in practice.
The uncomfortable truth: most AI projects fail on reliability, not intelligence
When banks say “AI is risky”, they rarely mean that the model is not smart enough. The real concern is whether the system behaves reliably in real conditions and over time.
In practice, the questions sound like this: can we reproduce the same result next week ? What happens when data is incomplete ? How do we detect regressions after a change ? How do we prove this will not break critical workflows ? And how do we audit the outputs under regulatory scrutiny ?
These are not AI problems. They are software engineering problems. That is why industrialization is the real differentiator.
Bank-grade AI is not achieved by adding more prompts and hoping for the best. It requires building a system whose behavior becomes measurable, testable, and monitorable, with clear mechanisms to correct issues and keep the solution governable as it evolves.
This is where many PoCs die. They look good in a demo, but they cannot be tested like proper software. TxAgent is designed to be testable by default, and we built the testing strategy around it from the start.
Trust is engineered, not claimed
For bank teams, trust is not a marketing statement. It is something a system earns through design choices that make its behavior predictable, controllable, and auditable over time. TxAgent was built with this in mind from day one.
First, TxAgent is not a general chatbot. It enforces a clear scope of what it is allowed to answer. If a question is out of scope, it is routed away instead of forcing an answer. This avoids “nice sounding” responses in areas where the tool should not be used.
Second, it maintains a curated golden dataset of validated questions and answers, including the rationale behind what is considered correct. This dataset acts as the regression reference for TxAgent. It evolves continuously as new use cases appear in real usage, and it can incorporate expert human-in-the-loop feedback to improve both coverage and quality.
Third, it treats ISO 20022 as a semantic backbone, not as a file format to parse. It reasons over the standard’s structure and meaning, which enables consistent, standard-aligned investigations across messages, roles, and payment chains.
Finally, it combines natural language flexibility with strict constraints (a hybrid approach, sometimes called neuro-symbolic AI). The LLM interprets the user question, extracts the business intent, and proposes a structured investigation path. But before anything is executed, TxAgent validates that the planned queries conform to the expected structure and constraints of the bank’s domain model. This ensures outputs remain structured, verifiable, and compliant with financial rules. When validation fails, TxAgent corrects and retries, adding another layer of robustness for production use.
The figure below (Figure 1) shows how TxAgent is designed to work in practice. It can be used directly by investigators and analysts through a UI, but it can also be called by upstream and downstream systems through APIs (e.g. using REST, MCP or A2A). This makes it possible to embed TxAgent into existing workflows, whether it is triggered by internal tools, case management, or other AI agents.
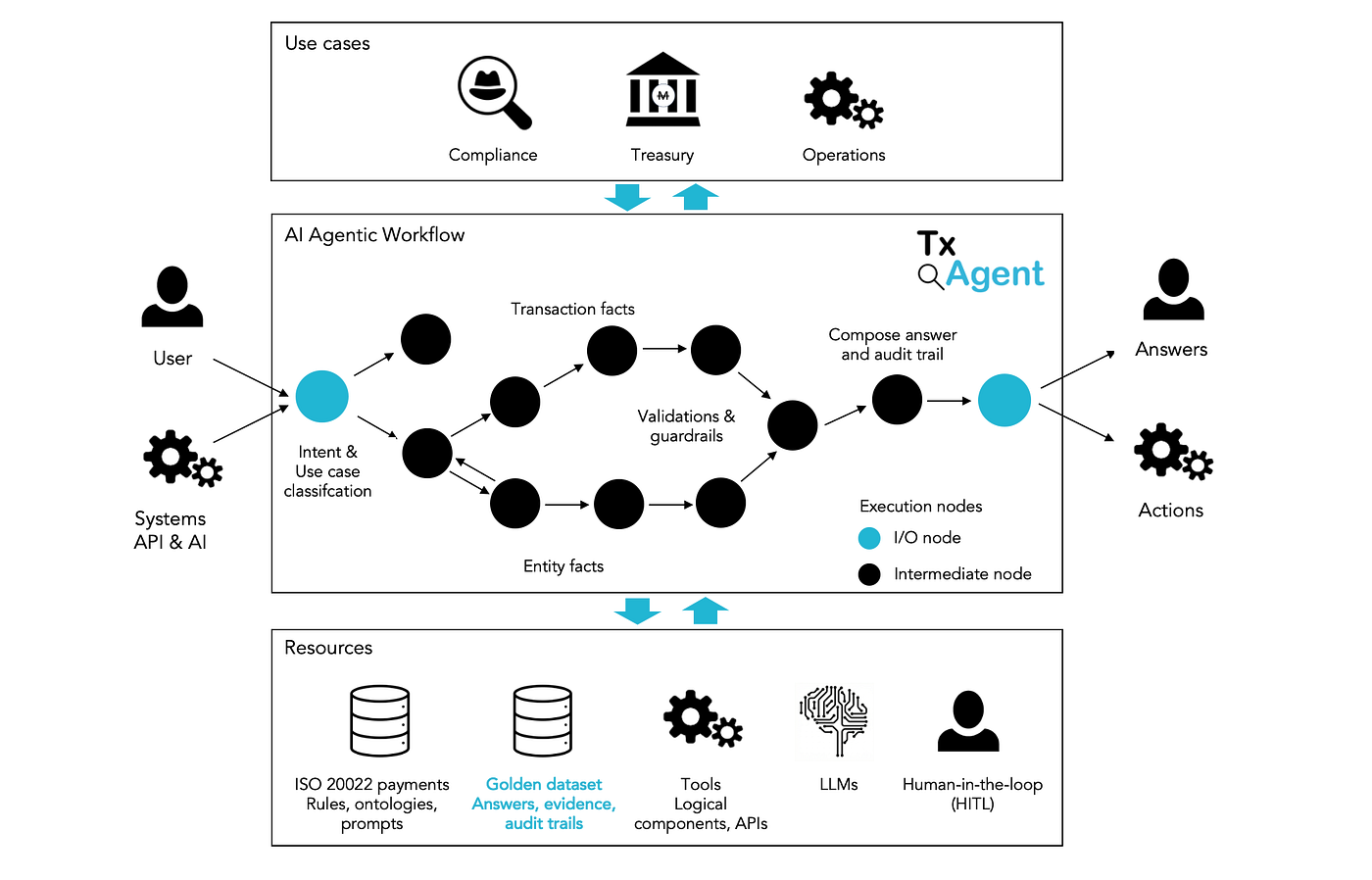
That is why TxAgent is built around evidence trails. Instead of producing a confident-sounding paragraph, it lays out the reasoning steps it followed, the exact fields and facts it relied on, and any cross-message links that were relevant. The result is a traceable path from the user’s question to the underlying evidence and then to the conclusion.
Investigation work is not only about speed. It is also about defensibility. This approach aligns with practical AI governance expectations, including auditability, repeatability, and controls, which are also reflected in emerging management standards such as ISO/IEC 42001.
What “Industrialization” Means for TxAgent
For us, industrialization means one thing: we can change TxAgent and still be confident it works across a wide range of scenarios, without breaking what worked yesterday. To achieve that, we need continuous proof of reliability, not occasional spot checks.
Reliability starts with the quality of the investigation itself. In Compliance, it means TxAgent does not miss relevant entities or transactions for a given pattern. The right items must be returned without false positive noise, and false negatives must be avoided. In Treasury, it means aggregated results are correct, for example when summing today’s inflows across accounts or filtering flows by corridor and counterparty. In Operations, it shows up when explaining why a payment failed, which fields are missing, and what needs to be corrected to release it.
But banks also care about how the answer is produced. The output must remain explainable, with clear evidence and traceable reasoning. It must be reproducible, so the same question on the same data leads to the same outcome. And it must stay within acceptable latency, so teams can use it in real investigation workflows without waiting minutes for each step.
The core challenge: how do you regression-test an AI investigation assistant?
Traditional software testing assumes deterministic outputs. If you run the same function twice, you expect the same result. With AI systems, this is harder. Language interpretation, retrieval choices, reasoning paths, and even response formatting can introduce variability, which makes classic “compare the exact output” testing insufficient.
So the question becomes practical: how do you test something whose wording can vary slightly, but still needs to be reliable? The answer is to test TxAgent the way a bank would evaluate it. Not by comparing the exact phrasing of a response, but by validating what matters: the underlying facts, the constraints, and the traceability.
For example, did TxAgent retrieve the right entities and transactions? Did it rely on the correct fields as evidence? Did it follow the allowed investigation logic and avoid restricted behavior? And did it produce an explanation that remains defensible and audit-ready?
To make this testable at scale, we define scenarios with known inputs, known questions, and clear pass or fail criteria. Each test case captures expected evidence boundaries and expected behavior, so regressions are detected even when phrasing changes. That is where Step becomes a key part of the industrialization process.
What we actually test, and why bank buyers should care
A typical TxAgent regression suite is designed around the same risks bank teams care about when they evaluate a solution for production. It is not about polishing a demo. It is about proving, repeatedly, that the agent behaves correctly under real conditions.
First, we test retrieval and context integrity. TxAgent relies on structured ISO 20022 data and connected entities, so the starting point must be right. We verify that it finds the correct transaction scope, identifies the relevant parties and roles, pulls the right address elements, and can follow links across multiple messages when needed. If the context is wrong, the rest of the investigation is irrelevant.
Second, we test evidence trail quality. Bank users do not just need answers, they need defensible answers. We check that key claims are supported by specific fields, that extracted facts are correct, that uncertainty is clearly signaled when data is incomplete, and that the reasoning remains explainable. In investigation workflows, trust comes from evidence, not from fluent language.
Third, we test stability across variation. Production data is messy. Fields can be missing, names can be inconsistent, message types can differ, and bank-specific conventions vary widely. We deliberately include this kind of variability in the test suite, because that is where most PoCs break when they meet reality.
Finally, we test operational performance expectations. TxAgent is an investigation assistant, not a real-time replacement for screening engines. Still, it must remain usable in daily workflows. We validate that it stays within acceptable latency, that it does not fail under parallel execution, and that performance remains stable as investigations become more complex. If the tool is too slow or unpredictable, it will not be adopted, no matter how good the output looks in a demo.
Why massive parallel testing is critical for AI success
To industrialize TxAgent, we needed a platform that can run investigation tests at scale with parallel execution, reproducible runs, and structured logs that keep results traceable across large regression suites. We also needed a setup where the test suite can grow continuously as new scenarios appear. Step provides exactly that. Built by Exense, Step has been used by banks and insurers for more than a decade to test and productionize business-critical systems [7], which makes it a natural fit for industrializing TxAgent.
But the point is not compute speed. The point is discipline.
As seen in the below figure (Figure 2) Step allows us to run large regression suites in parallel and make validation part of the normal development cycle. Every change must survive the test suite. Failures become visible immediately. Trends in quality and latency become measurable over time. Improvements can be proven with evidence, not claimed in a demo.
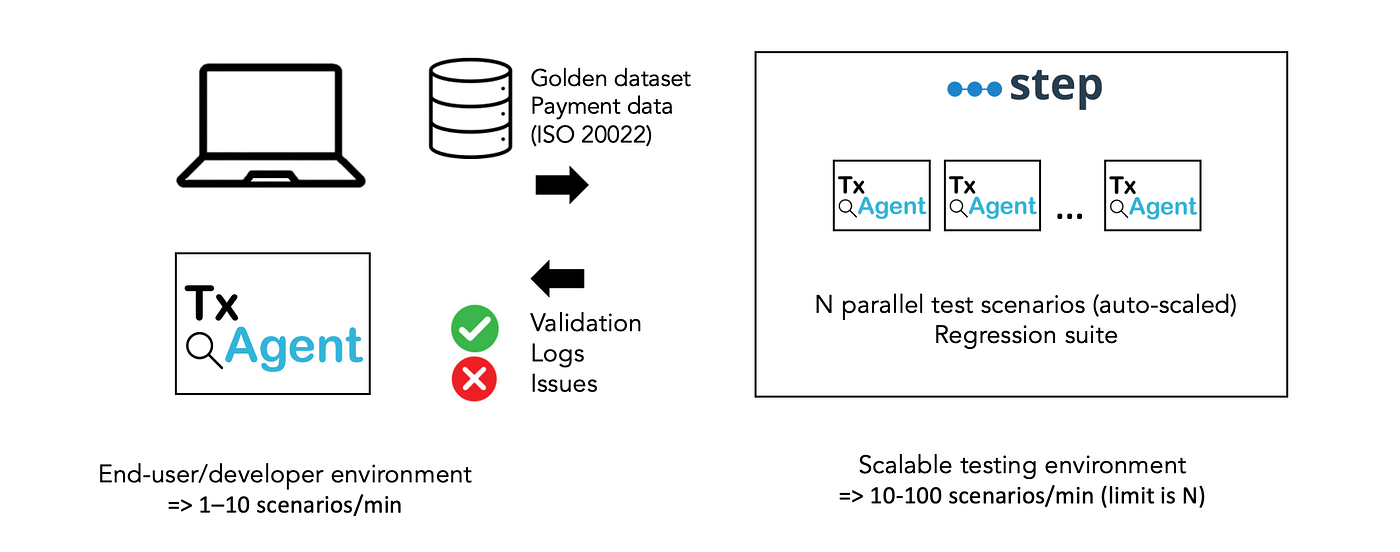
Depending on the parallelization factor N, we can execute large regression suites in a fraction of the time. In our case study, local runs typically validate around 1–10 scenarios per minute, while Step allows us to run 10 to 100 scenarios per minute (or even more) in parallel on a cluster, depending on cluster capacity and scenario duration. The upper limit is defined by available nodes in the cluster given a number of scenarios and their respective execution time. More details on the test protocol and results can be found in “Step for Testing AI Agents” [8].
This changes what you can promise. Without massive parallel testing, teams rely on hope: “we think it works”, “we tested a few scenarios”, “it looked good in the demo”. With it, you can speak in bank-grade terms: “this change passed the regression suite”, “we improved X without breaking Y”, and “we have evidence for release readiness”. That is what moves an AI system from interesting to deployable.
Use cases banks can fund now
Let’s be direct. Most banks no longer allocate budget to “AI innovation” as a category. Budget is allocated to solve concrete operational and risk problems, with clear owners, KPIs, and pressure to deliver value.
TxAgent is built for exactly those areas. It supports investigation workflows where teams already spend time and money today, and where better speed and better context immediately translate into impact.
1) Faster AML and screening investigations, with better context
Screening and monitoring systems generate large alert volumes, and too many of those alerts require manual work to confirm that nothing is wrong. The cost is not only analyst time. It is also delayed payments, operational overhead, customer friction, and growing investigation backlogs.
TxAgent helps investigators get to the relevant context faster by turning raw ISO 20022 messages into structured evidence. It can surface the involved parties and addresses, highlight inconsistencies and missing elements, and connect related payments when the investigation spans multiple messages. The goal is simple: help teams reach a defensible conclusion faster, with less manual gathering and less uncertainty.
2) Treasury and liquidity insight grounded in real transaction flows
Liquidity reporting is often disconnected from what is actually happening in transaction flows. Treasury teams do not just need dashboards. They need fast answers to concrete questions like where settlement delays build up, which flows drive volume in a given period, and where timing issues might create liquidity pressure
TxAgent connects ISO 20022 transaction structure to investigation-style analytics. It does not replace forecasting engines or core treasury systems. It provides a decision-support layer that helps teams understand what the real flows show, with traceable evidence behind the result.
Across these three areas, the common theme is the same: banks already pay for these workflows today. TxAgent is designed to reduce time-to-answer and increase confidence in the outcome, without requiring a full rebuild of existing platforms.
3) Payment repair and exceptions, with lower operational friction
Payment repair is one of the most underestimated cost centers in transaction banking, and also one of the most fixable. Exceptions typically happen because data is incomplete, message structures vary, clearing requirements are not met, address formats cause rejection, or party identifiers do not match expectations.
TxAgent supports operations teams by explaining why a payment failed, which specific fields are missing or inconsistent, and what needs to be corrected to release it. It can also help identify recurring patterns, such as repeated repair reasons by corridor or counterparty.
The bigger point: how to ship AI in a bank
Banks do not only want AI solutions. They want confidence that AI can be brought to production safely, especially in regulated and business-critical workflows. This is why the work behind TxAgent matters beyond the product itself.
Many AI initiatives get stuck after a promising PoC because the hard questions remain unanswered: how do we validate quality at scale, detect regressions after changes, and keep outputs consistent and auditable over time ? The gap is rarely about intelligence. It is about delivery.
TxAgent is built around a repeatable approach called evaluation-driven development (EDD) that banks can recognize as “production thinking”:
- Define clear use case scope and expected behavior
- Produce evidence-backed and explainable outputs
- Measure quality through regression scenarios
- Run validation continuously at scale
- Treat reliability as a first-class feature, not a side task
This is what makes AI usable in practice. When a system can be tested, monitored, and improved without breaking existing workflows, it becomes something teams can trust and adopt.
It is the difference between innovation theatre and real production adoption.
What this means for banks and partners
ISO 20022 is now in place across the industry. The structure exists, the data is flowing, and every payment carries more meaning than MT ever could. The question is no longer whether the migration worked. It did. The real question is how banks turn this new structure into operational value.
TxAgent is designed with TxFlow as part of an ISO 20022 intelligence layer. It does not replace existing screening engines, payment platforms, or treasury systems. It sits on top of them and makes the data they already produce usable for investigations, decisions, and audits. It turns structured messages into explainable insight, backed by evidence and validated through continuous testing.
For banks, this means a pragmatic path forward. TxAgent is engineered for production adoption, not as a standalone demo. Its scope is deliberately focused on investigation workflows, where faster clarity and defensible answers matter most. Massive parallel testing is not a marketing story. It is the mechanism that makes the solution safe to rely on as it evolves.
For partners, this approach shows how AI can be integrated into regulated environments without breaking existing architectures. An ISO 20022 intelligence layer becomes a shared foundation for compliance, operations, and treasury use cases, while respecting control, auditability, and performance constraints.
If you are exploring how to extract real value from ISO 20022 beyond migration, or how to move AI from pilots into production in a bank, this is the conversation to have.
About Alpina Analytics
Alpina Analytics builds ISO 20022-native tooling for banks, including TxFlow and TxAgent, an investigation assistant that turns transaction data into evidence-backed answers across compliance, treasury, and operations.
Our team brings hands-on experience from real-life banking use cases and production deployments in tier-1 banks. We build with the constraints of regulated environments in mind, with a strong focus on reliability, explainability, and integration into existing workflows.
If you are exploring ISO 20022 intelligence beyond migration, reach out to us !
References
[1] https://medium.com/@pierre.oberholzer/iso-20022-road-to-riches-4618e029dbf8
[2] https://medium.com/@pierre.oberholzer/iso-20022-navigating-rich-semantics-7571ea76f8a2
[3] https://www.techradar.com/pro/companies-confess-their-agentic-ai-goals-arent-really-working-out-and-a-lack-of-trust-could-be-why
[4] https://www.swift.com/sites/default/files/files/its-time-to-transform-exceptions-and-investigations-april2025.pdf
[5] https://www.ey.com/en_ch/cfo-agenda/dna-treasurer-survey
[6] https://www.bis.org/cpmi/publ/d215.pdf
[7] https://step.dev/blog/whitepaper-unified-testing/
[8] https://medium.com/@exense_step/testing-ai-agents-with-step-5a43639db916